Step 1: Uploading a new file
Note: Data Loader only accepts Delimited Files. They can be either comma, pipe, semicolon, or tab delimited.
Single Files:
To upload a file (or files), the user can either use the Upload File Button from the home page or drag-and-drop the file into the File List. The Upload File Button will open up a standard file browser, allowing the user to search their system for the desired file.
Once you’ve selected the file(s) to upload, you’ll need to set a template (optional), a delimiter (defaults to comma), and Keywords (optional), before selecting ‘Upload’.
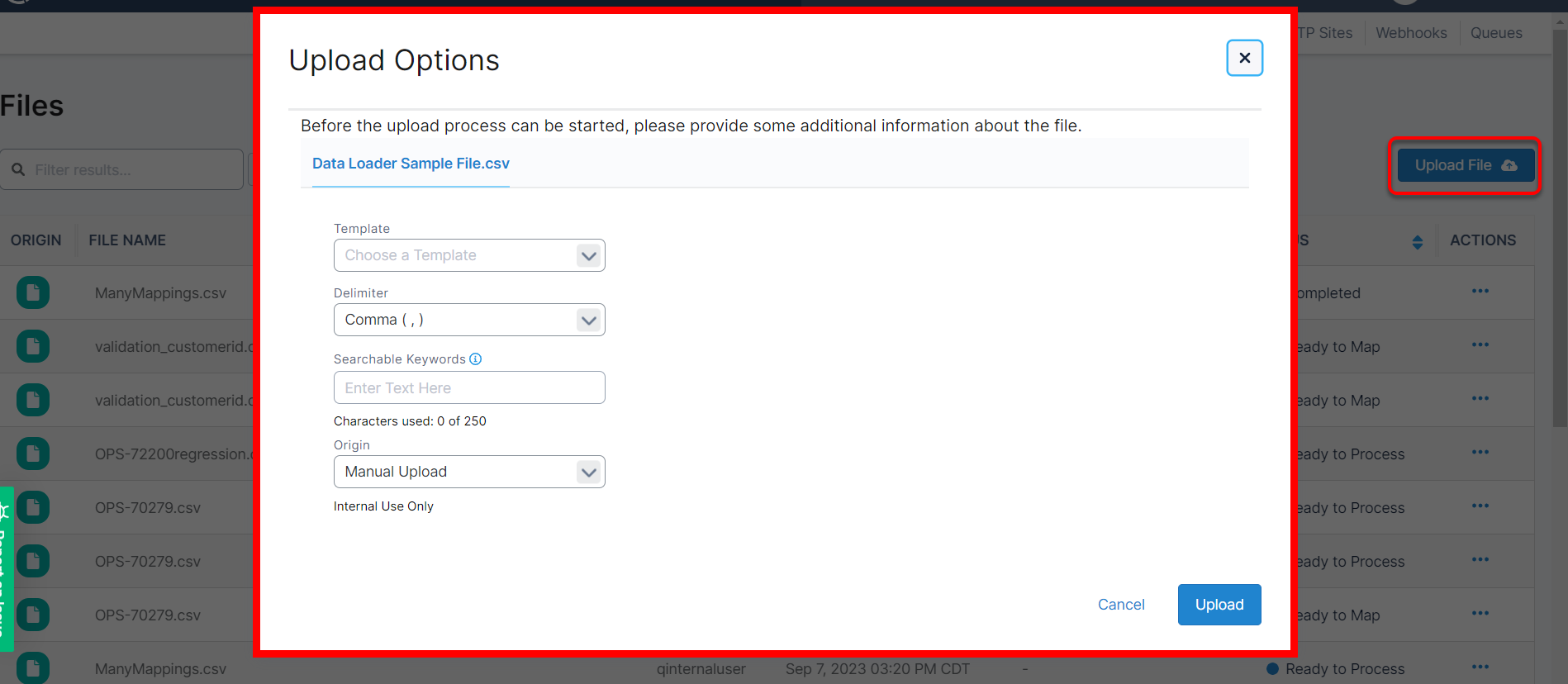
To save time, you can select multiple files to upload at once.
File Status: Uploading
Immediately after hitting ‘upload’ you’ll be taken back to the home screen where the file(s) you selected to upload will be listed. Initially they will have an Uploading status.

Depending on the size of the file, it may stay Uploading for some time. You can check how many rows have processed and which file(s) are next on the Queues page.
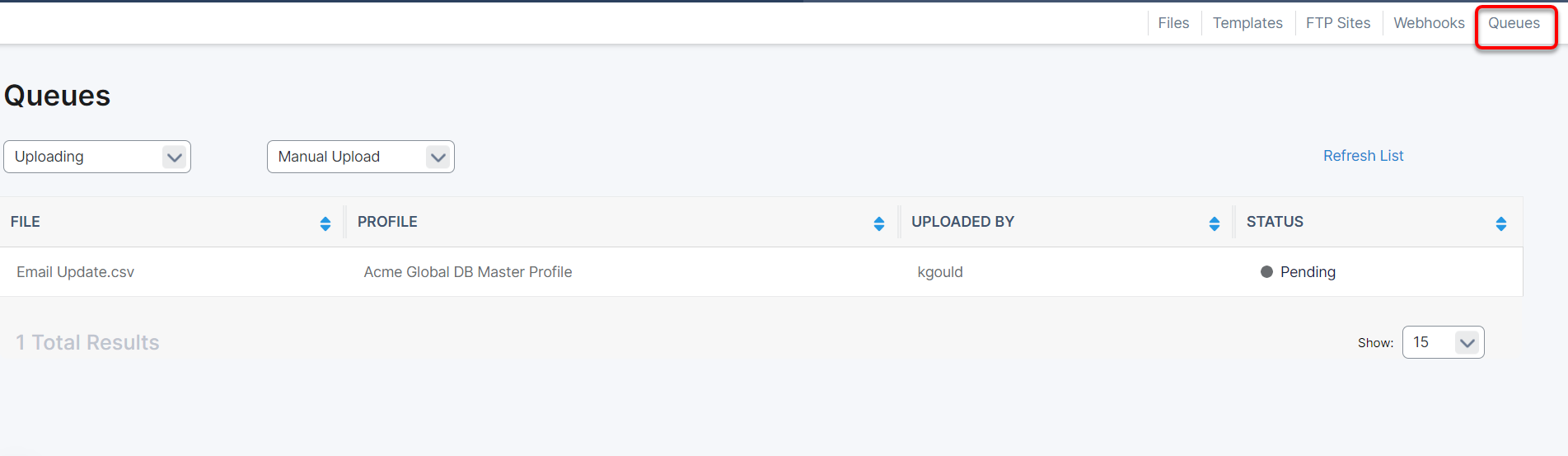
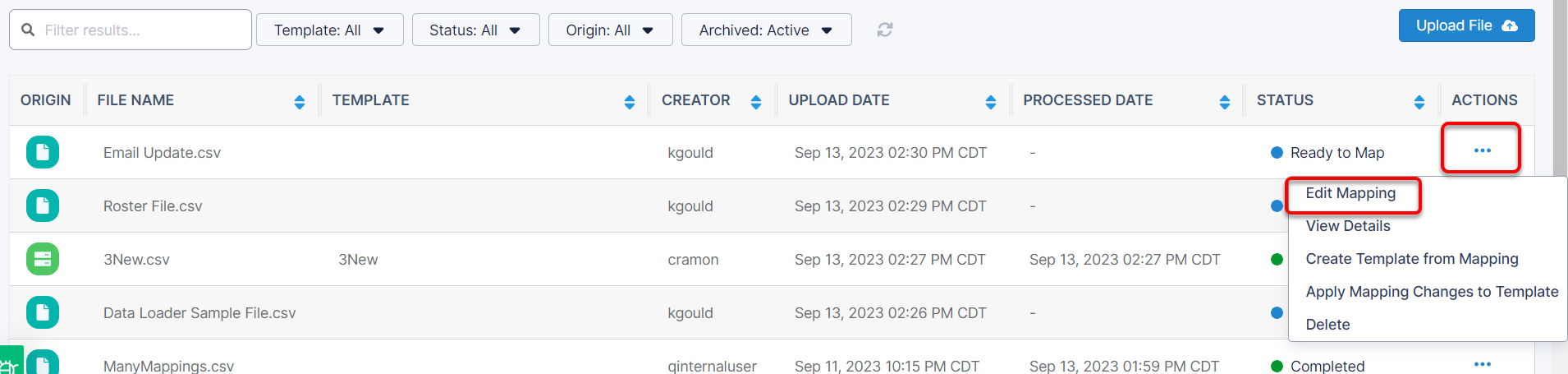
File Status: Ready to Map
After the file has been uploaded successfully, it will be given a status of Ready to Map.
To begin mapping, select “Edit File’s Mapping” from the Action Menu.
Step 2: Mapping
A standard file has three parts of mapping you’ll need to review before the file can be processed:
-
Overview
-
General Mapping
-
Settings
Depending on what information your file contains, the standard steps may change and new steps can be added (i.e. if you’re updating a behavior or demographic).
The following are additional steps that may be added depending on the incoming data and how it has been mapped:
-
Demographic Mapping
-
Product Class Mapping
-
Deployment Type Mapping
-
Behavior Mapping
-
Behavior Attribute Mapping
-
Contact Mapping
-
Processing Rules
-
Source Priority
Overview Page
The first part of the mapping is an overview page that shows all of the incoming data from your file.
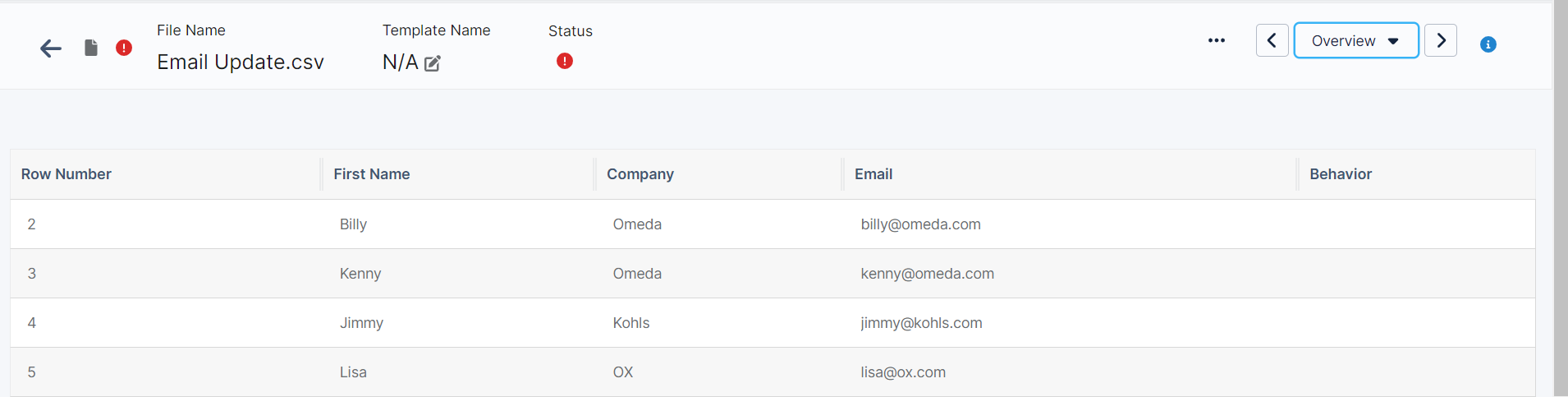
File Navigation
All navigation within a file mapping is located across the top of the window.

The file name will display in the upper left-hand corner.
For the General Mapping step, the Add Constant button will appear in the upper left-hand corner. This will allow you to add additional fields to your file without manipulating the source file.
The Save button will always be present in the upper left-hand corner and will allow you to save throughout the mapping process.
The Status Section will display general file information, warnings and errors (see details below).
The navigation dropdown will allow you to jump between any steps, while the left and right arrows will move you to the previous and next step, respectively.
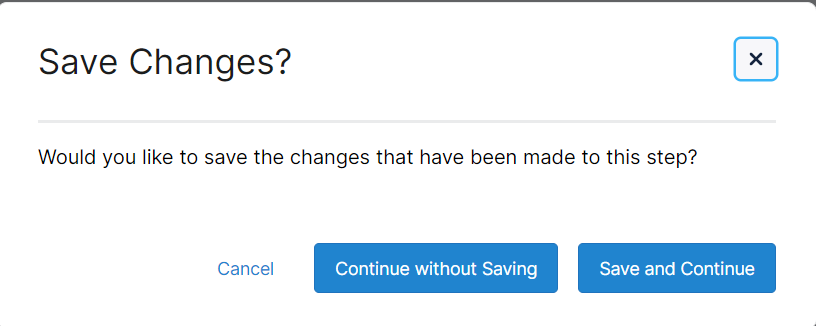
After each step you will be prompted to either Continue without Saving or Save and Continue.
-
Cancel will close the dialog and return you to the current step
-
Continue without Saving will proceed to the selected step without saving mappings from the current step
-
Save and Continue will save the changes and proceed on to the selected step
File Status
Information, Warnings and Errors are all tracked in the file header in the upper right hand corner. Clicking into each of these will bring up the note(s) on what each notification means.
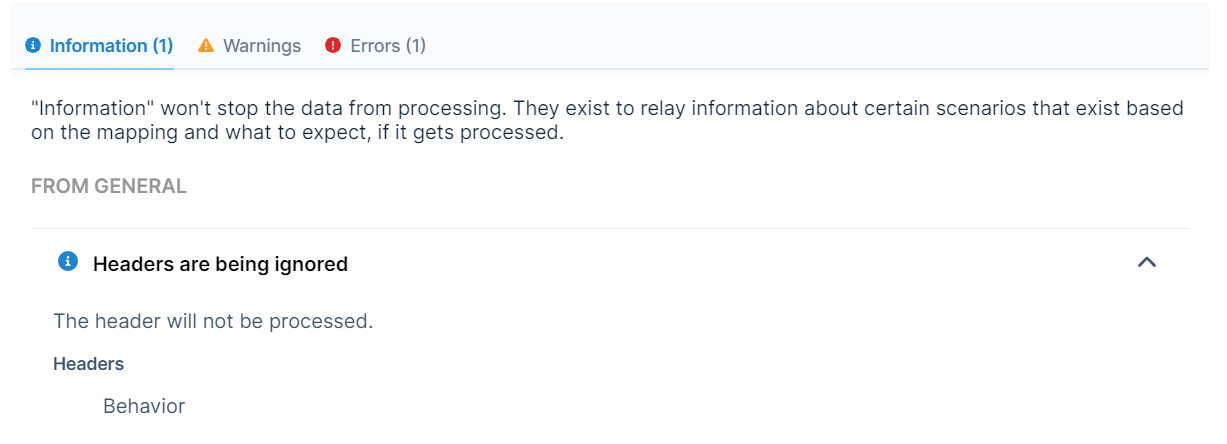
Information: These notices won’t stop the data from processing. They exist to relay information about certain scenarios that exist based on the mapping and what to expect if it gets processed.
Warnings: These notices relay information regarding something about the file they may not be recommended. The file will still process, but there may be complications.
Errors: These notices will prevent files from being processed and must be fixed in mapping.
General Mapping
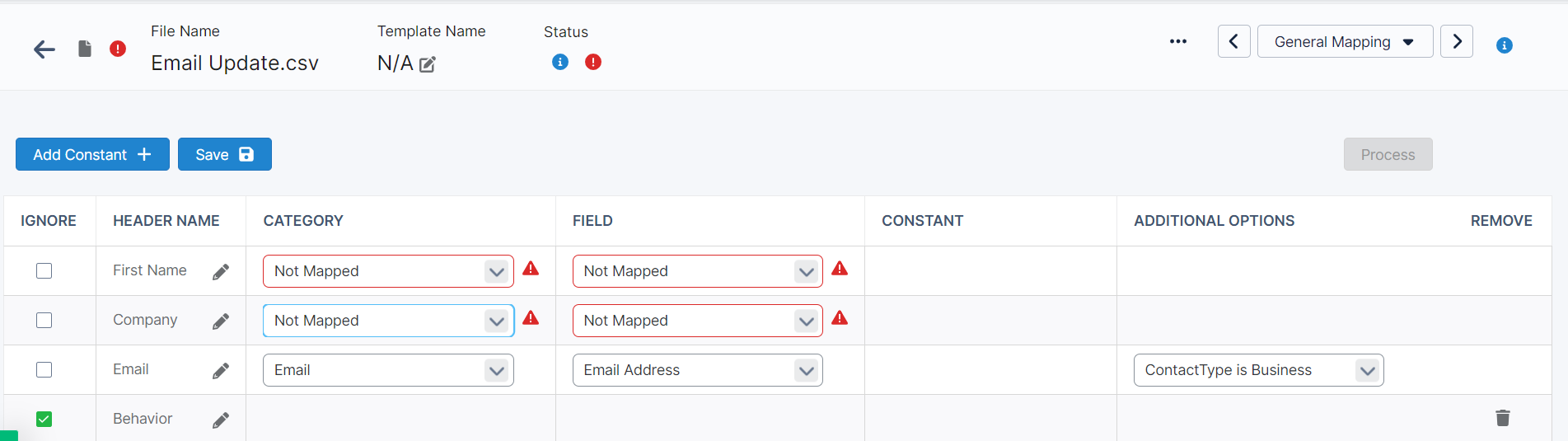
The overall goal of this step is to map incoming headers (bold text on the left) to their equivalent Omeda fields (white drop-downs on the right).
-
During the upload process, some of the fields may have been identified and already mapped. These are to be viewed as suggestions and can be changed by the user as they see fit. Any field that could not be matched will be set to –Not Mapped– and highlighted in red. You can leave fields un-mapped and they will be ignored during processing and not committed to the database.
-
Entire headers can also be Ignored by checking the box under the header name.
-
By default, most contact fields are considered of the Contact Type “Business”. This can be changed by the User by choosing another available option. It is important that the user makes sure all relevant fields have a matching Contact Type. If the file contains a way to identify an existing customer, then mapping contact information will cause a new step to appear.
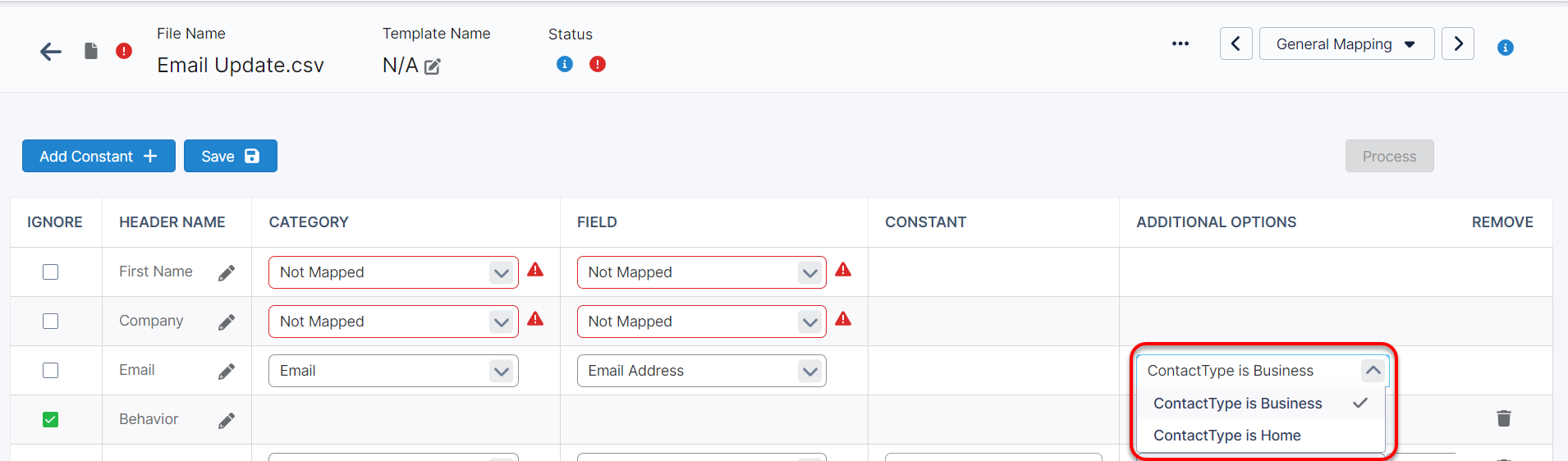
Note: If it is setup that all of the fields are tied to the Contact Type “Business” except, for example, City is set to “Home”, then it will result in two different incomplete addresses.
Duplicating Headers
If there are headers in the file that you would like to duplicate the incoming value and store in multiple place in your database, use the action menu and select “Duplicate”. This action will duplicate the header row, allowing you to map the single header to another field.

Adding File Constants
If there are headers that you would like to add to the file during mapping, you can click ‘Add Constant’ under the file navigation.
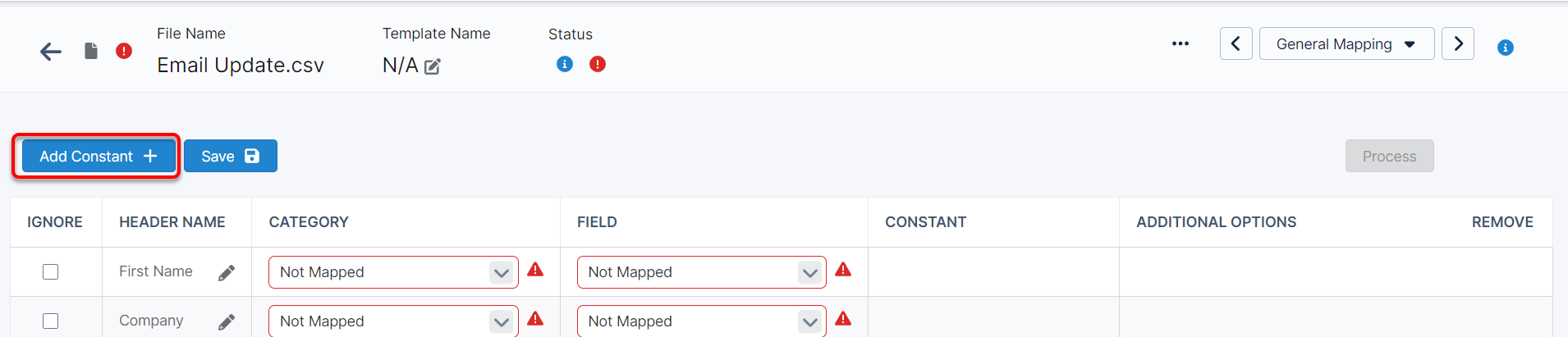
A pop-up will appear prompting you to name the constant before adding it to the mapping section
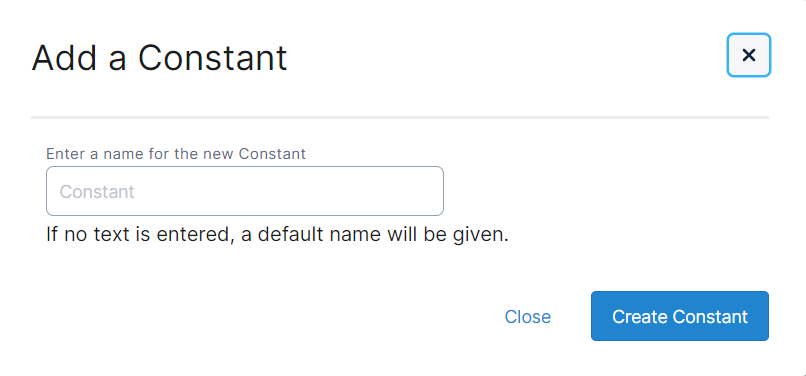
Once you’ve named and created the constant, you can map it to an incoming field (e.g. promo code) and provide a value that will append to all of the rows in your file.

Example: Your new constant field maps to the Promo Code field in the database – your constant in this case could be telemarket1219 (telemarketing file for Dec 2019).
Example 2: You want to map all contacts on the file to a specific behaviors such as attended an event. In this case, your constant may be a numeric value that you can map to a specific field in the behavior mapping section. (e.g. #1 which you can map to ‘Attended’ )
Validation Rules
Validation Rules Show/Hide based on the Fields the User has mapped in General Mapping Step. The user must map at least one of the linked fields for a Validation Rule to be selectable in the Validation Rules step. Some rules are turned on automatically, such as filtering out vulgar records, but any can be unchecked.
-
The majority of these options are validation checks to be performed on that data. If a piece of data fails a validation, then that row will not be processed. Any row that passes validation will continue on to be processed. Depending on the selected rules, a single field can cause the whole row to fail. An example would be the Postal Address Required validation rule. It requires that most of the fields exist for a complete address. Therefore if a field such as city is missing, that row will fail.
-
It should be noted that some validation rules overlap. For example, Reject New Customer would overlap with Customer Id Required, Customer Id Not Found, and/or External Id Not Found. This is because any of the three rules are looking for existing customers and if they don’t find any, the row will fail anyways. There are many rules that work similarly, but different just enough to be separate. While there shouldn’t be an issue running all of the rules together, keep in mind that an overlap in what’s being checked may exist and that the reason for failing might be ambiguous if both specific and general rules are applied.
-
When a record processes through Data Loader without state information, but does have a valid US zip code, the state code will be populated based on the state that zip code resides in.
If you have any questions, please contact your Audience Services team and they will walk you through which rules are best applied to your file.
A full list of the rules and additional explanations can be found here.
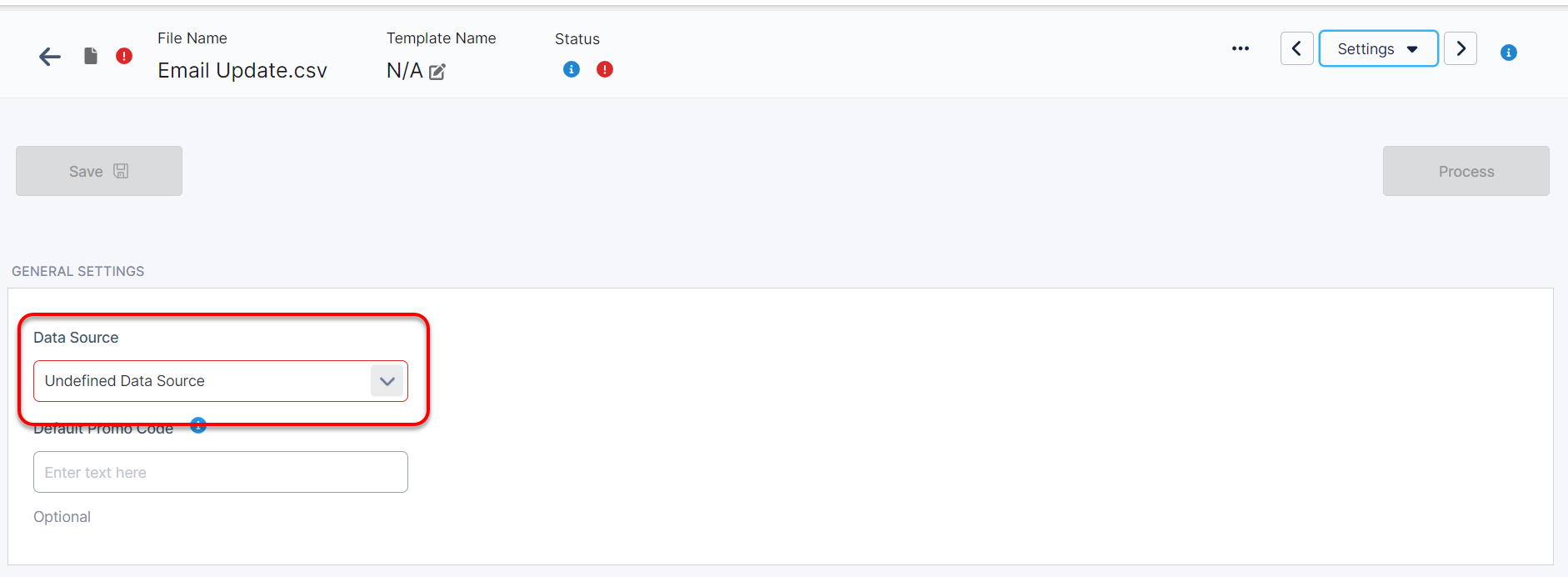
Settings
At the top of the settings page is where you must set your Data Source. Files cannot be uploaded without a Data Source selected. If you’re unsure of what Data Source to choose, you may proceed by selecting ‘Sources Other – Other’ in the dropdown.
If the correct data is available, then the following Match Related Settings will be checked by default. You can always un-check them if they do not apply:
-
Name + Address Match
-
Name + Email Match
-
Name + Phone Match
-
Exact Email Match
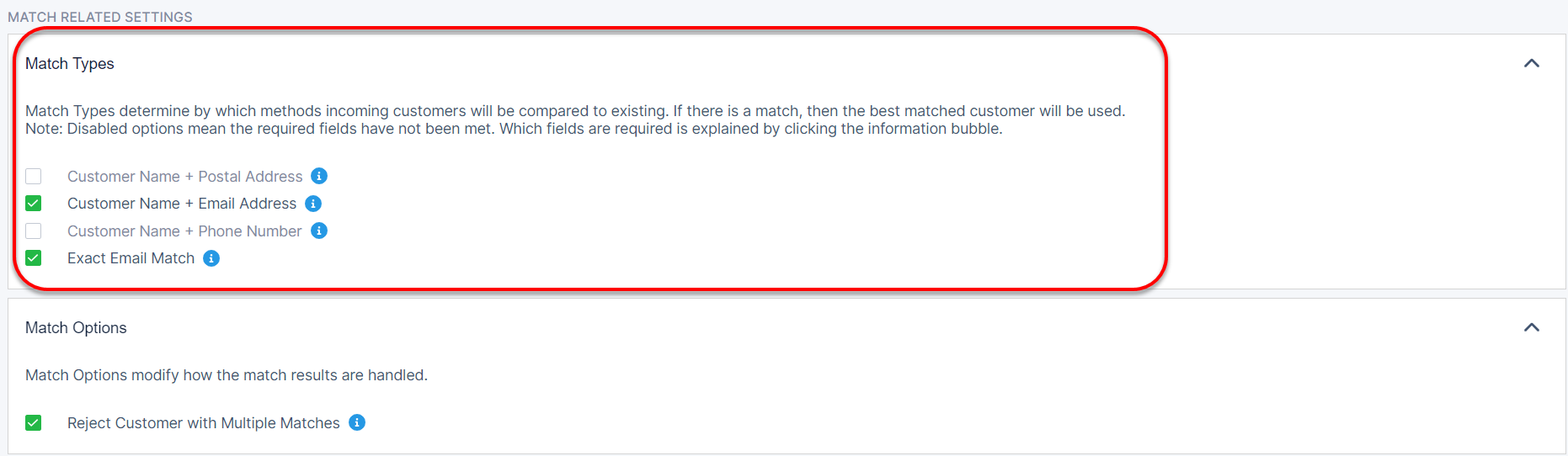
This list of validation and pre-processing rules will help match your incoming data to existing customers in your database. It will also allow you to choose what happens with data that may not match.
If you have any questions, please contact your Audience Services team and they will walk you through which settings are best applied to your file.
Finish Mapping
Once you have mapped the file, there are one of two statuses that may be applied:
-
Mapping Incomplete
-
Ready to Process
Mapping Incomplete appears if the Mapping has Errors in it. These are things that must be addressed before Data Loader can move forward and process that file.
To correct this, re-visit the mapping sections to make sure required fields are in place.
Ready to Process means that the Mapping is in a state that it can be processed. Warnings may still exist in the Mapping, but as stated above, warnings do not prevent processing. At this point, you can now move to Processing the file.
Step 3: Processing
Once your file has a status of ‘Ready to Process’ you can commit the data to your database.
To begin, choose “Process” from the actions drop down:
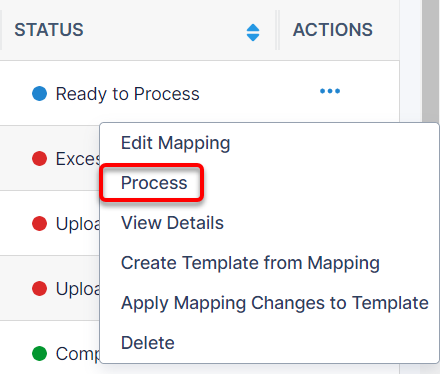
Each time you go to process a file, you will see the following warning that the process will make changes that are not easily reversed.
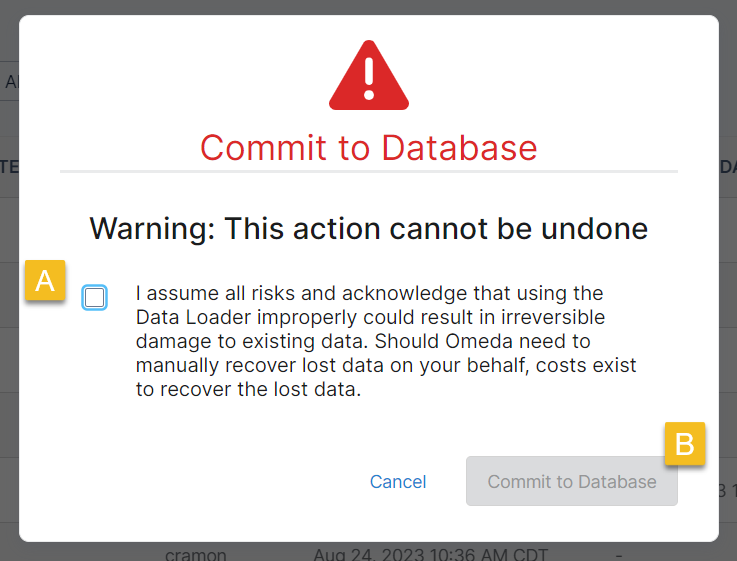
Accepting these terms will enable you to press the Commit to Database Button. Pressing this button starts the processing cycle, which runs in the background and cannot be interrupted.
Processing Steps
Data Loader’s processing component is made up of two stages:
-
Pre-Processor: This stage is responsible for validating the data
-
Processor: This stage generates any new data and modifies existing data based on the Mappings you’ve set up
Once you’ve started to process the file the status will change to ‘Processing’. You will be able to track the file as it moves through these two stages in the Queue Section:
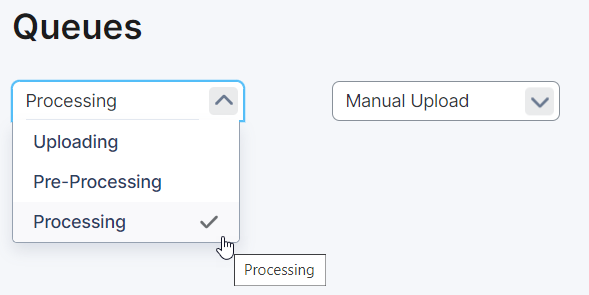
When everything is a done, the user will receive an email stating everything complete. It will contain some basic info and a small report of the overall results. In the event that there is an issue, it will notify you accordingly.
Note: Audience Builder is not rebuilt as part of this. Before the customers can be used in Audience Builder, it will need be rebuilt. Audience Builder is rebuilt nightly. Please contact your Audience Services team if you need it to be rebuilt ahead of the nightly build.
After a File has Processed
When everything is done processing, the file status will update depending on how well the Processing stages went.
Status messages include:
-
Completed – All of the rows in the file have processed successfully.
-
Completed w/Errors – The file has been partially processed; some rows were completely processed, while others were not. The errors can be viewed in View Row Errors option from the file’s menu.
-
Excessive Errors – If 60% or more of the file contains errors, the file will not continue processing. If this occurs, the file can be deleted and re-uploaded once corrections have been made.
-
Processing Failure – This status means that an internal server error occurred and the file was not processed completely. When a file has this status, we are notified internally, but you will need to file a JIRA ticket and notify your Audience Service team so the issue can be addressed.
-
The information in that ticket should include:
-
Name of the File that was Processing
-
Name of the Client
-
Name of the Profile (if applicable)
-
Around when the Failure occurred
-
-
A confirmation will also be sent to the user when processing completes. The confirmation email will include a summary of the number of input rows, number of rows processed and number of rows with errors. The confirmation email will also include the Data Loader Tracking Code.
Rows with Errors
If your file is marked ‘Completed w/Errors’ you can view a full listing of each error by clicking ‘File Details’ from the actions drop down:
The popup window that appears will list each row # that triggered an error, along with a note of why it failed.
If you would like to correct any of these errors you will need to isolate the rows in the original file and re-upload them.
A future enhancement will allow you to correct and commit the errors from within the tool.
Reviewing File Details
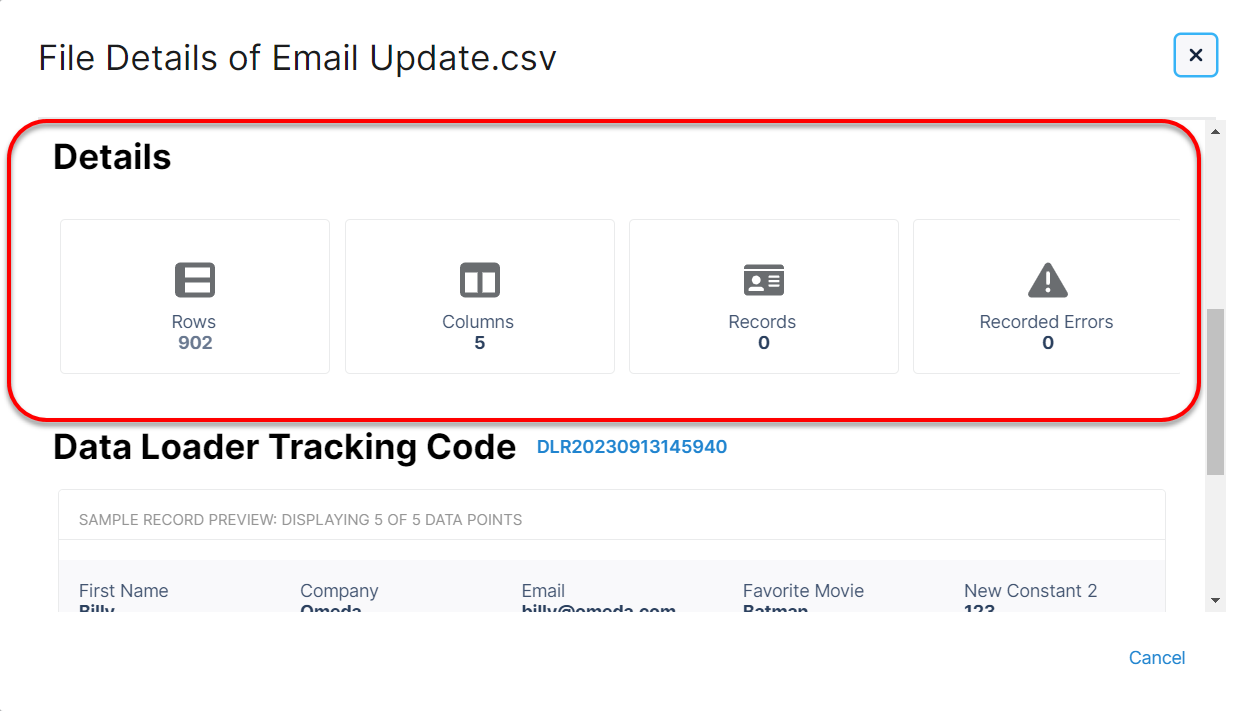
The counts of rows which processed versus those that received an error can be viewed in the Details section of the View Details Modal (Actions Menu > View Details). Records represents the number of successfully processed rows, while Record Errors is the number found with an error.
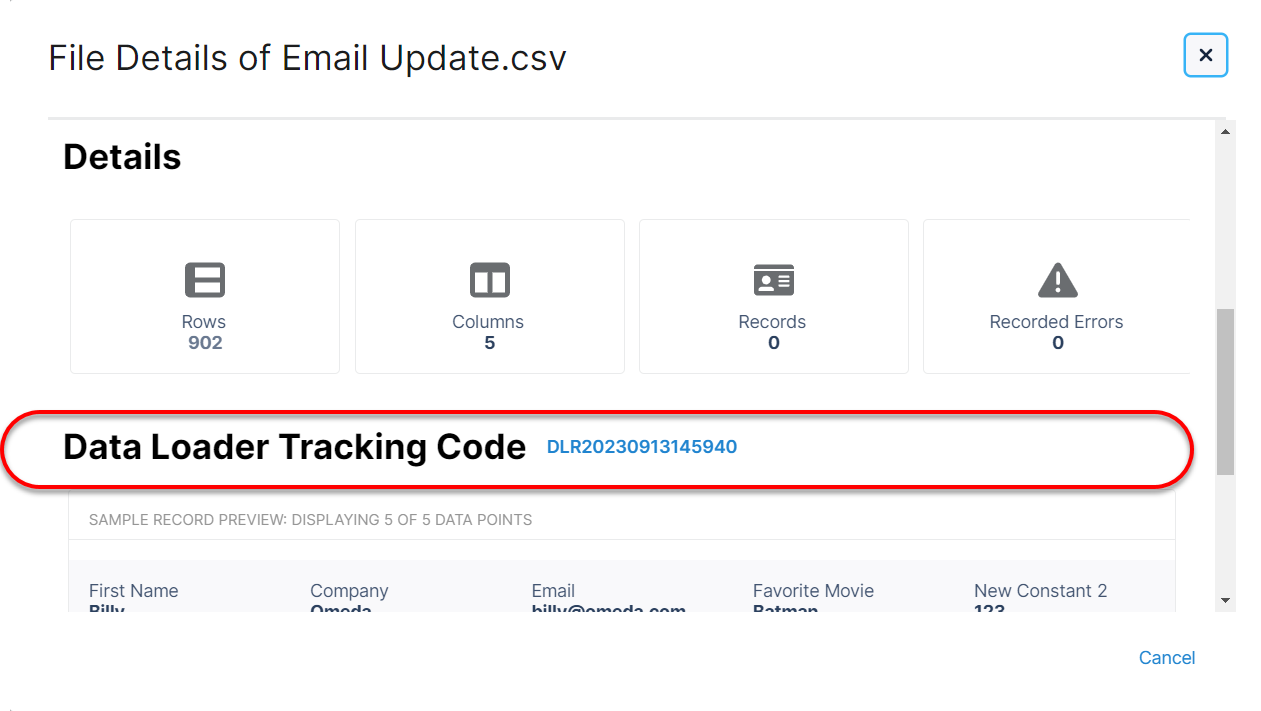
Once it has been processed, each file gets its own Batch Tracking Code which can be used to track customers and their data related to the uploaded file. You can also use this code to lookup the audience within Audience Builder. Clicking on the code will give you the option to copy it your clipboard or open it automatically in Audience Builder.
Archiving Processed Files
Once a file has been successfully processed and is marked ‘Completed’ you can remove it from the list of current files by choosing to ‘Archive’ it from the Action menu dropdown.
Note: Completed files cannot be deleted, since they have already been converted to the database.
To view files that you have previously archived, select ‘Archived’ from the ARCHIVED filter drop down at the top of the homepage and then click the blue ‘Search’ button.
To restore a file that was previously archived, click ‘Restore‘ from the Action menu dropdown.
Table of Contents