In today’s data-driven landscape, seamless integration between platforms is essential for streamlined operations and maximizing efficiency. With the integration between AWS S3 and Omeda, businesses now have a powerful solution to effortlessly manage and leverage their data. This integration enables users to seamlessly upload and process files stored in their AWS S3 buckets directly into the Omeda platform.
The AWS S3 integration found in Data Loader automates the file ingestion process and will look for files meeting specified criteria to pull in from an S3 Bucket and process nightly into Omeda.
Note: This feature requires additional permissions to be turned on. If you do not yet have access to this feature, please submit a support ticket.
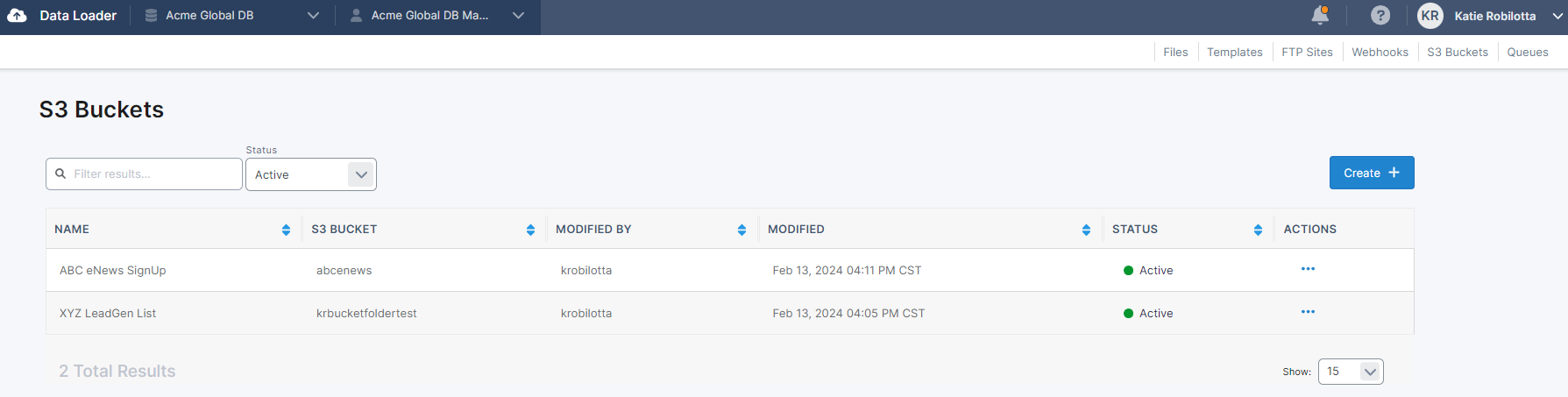
S3 Bucket Dashboard
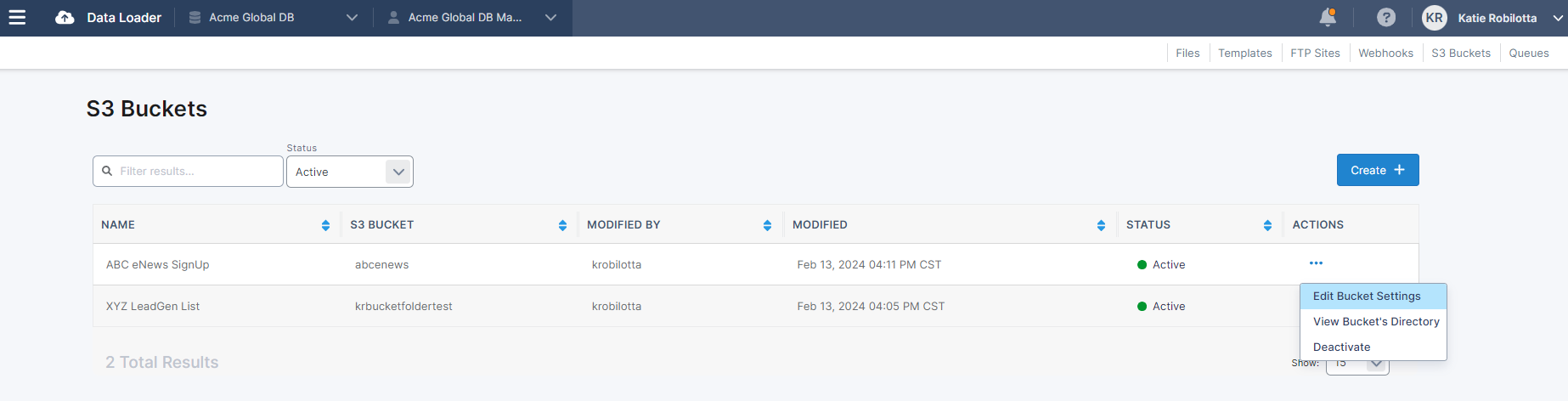
Clicking on ‘S3 Bucket’ in the Data Loader menu will bring you to the list of S3 Buckets you have already connected to.
Create
To connect to a S3 Bucket in Data Loader, click ‘Create’ at the top right side of the site list.
This will open a popup that prompts you to name the S3 Bucket connection:
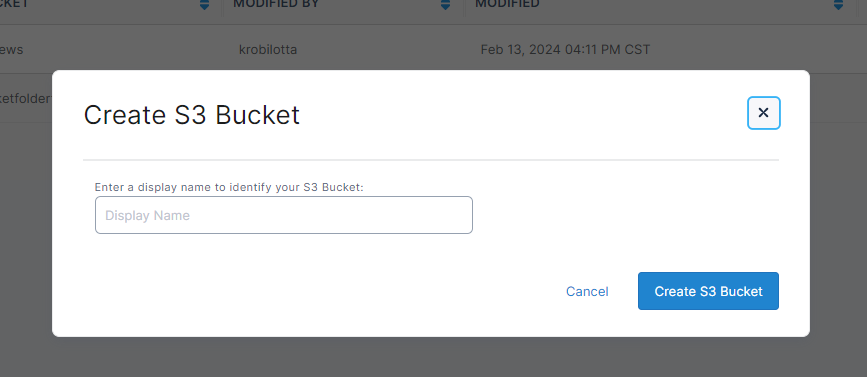
Once you’ve named your new S3 Bucket connection and clicked ‘Create S3 Bucket’ you will be taken to the settings page.
Settings
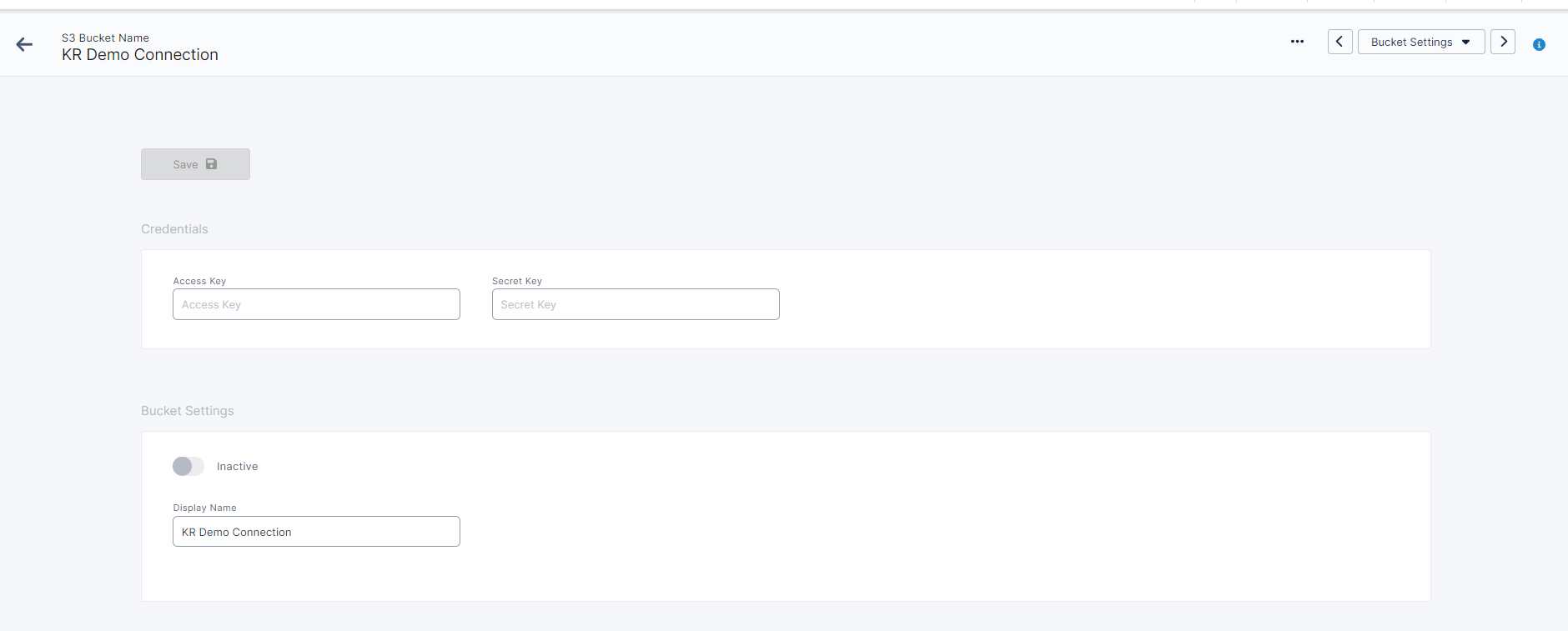
For a successful setup, you will need the following things:
-
Access Key and Secret Key provided in your AWS Console.
-
The Region where the bucket is located. This can also be found in your AWS Console under the bucket’s properties.
-
Once the Access Key and Secret Key are provided and saved, a dropdown field will appear under Display Name that will be populated with the connected account’s S3 Buckets found within the selected Region.
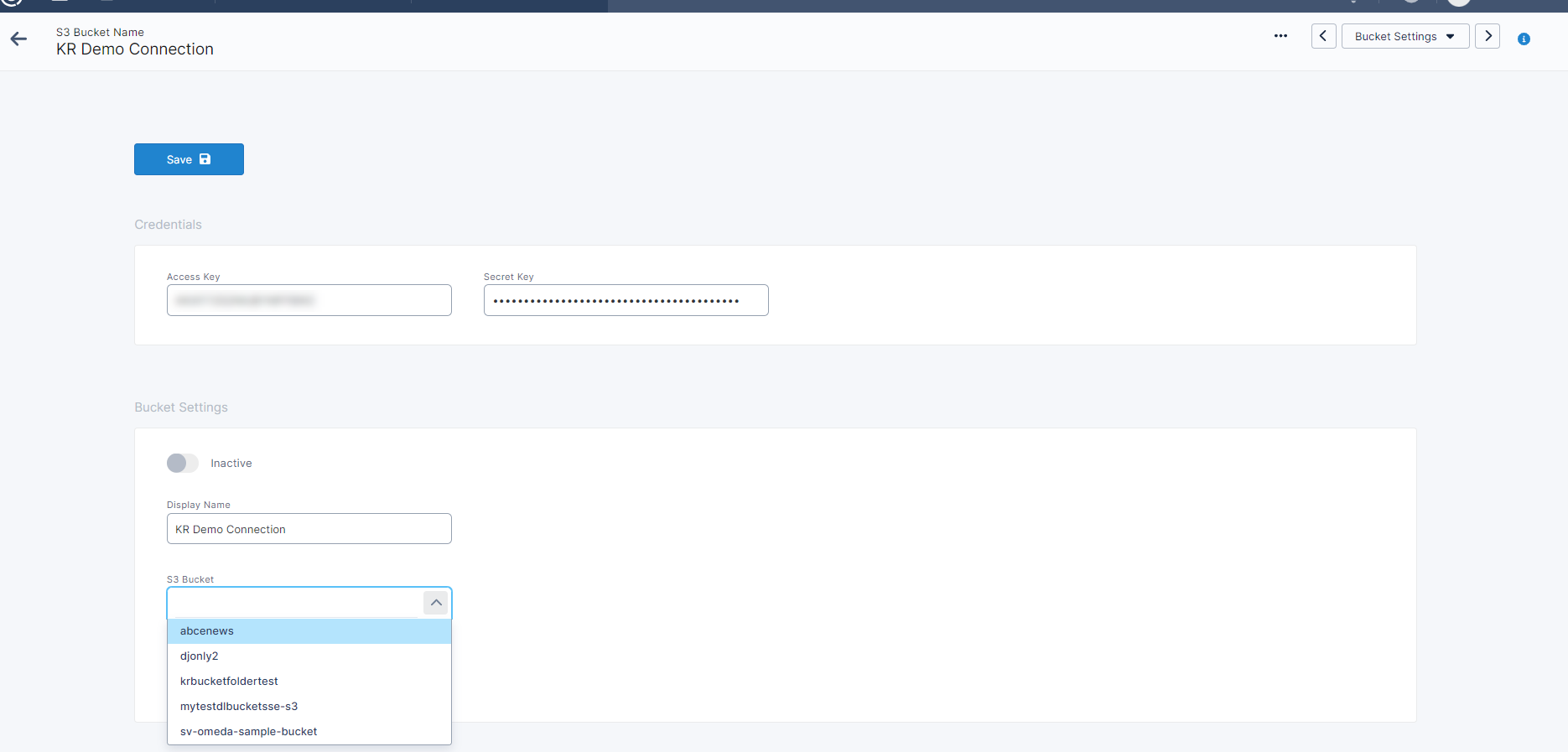
S3 Bucket Navigation
To view the Bucket’s settings, view the file list, or deactivate the S3 Bucket connection, use the action menu drop down on the desired S3 Bucket.
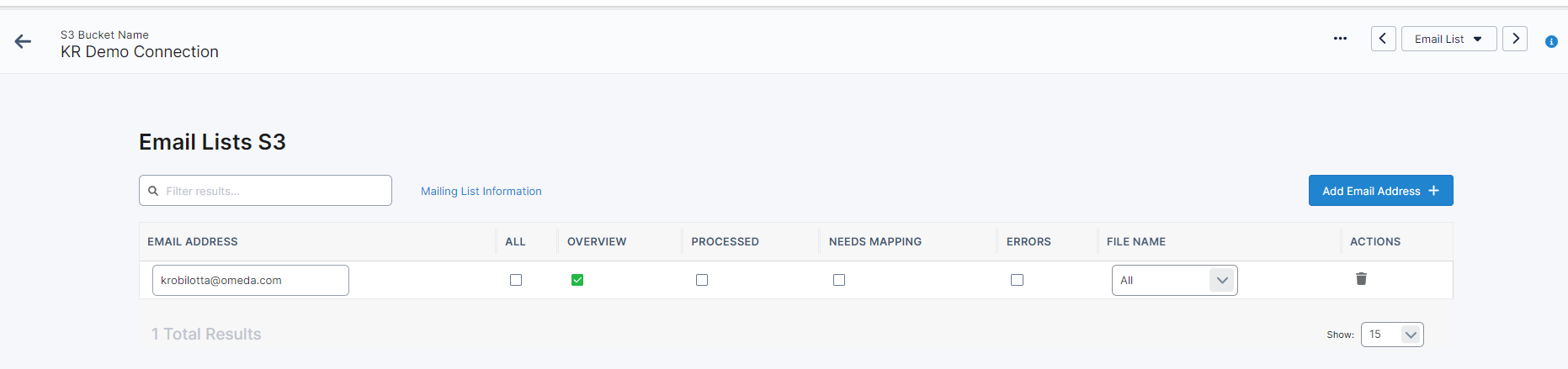
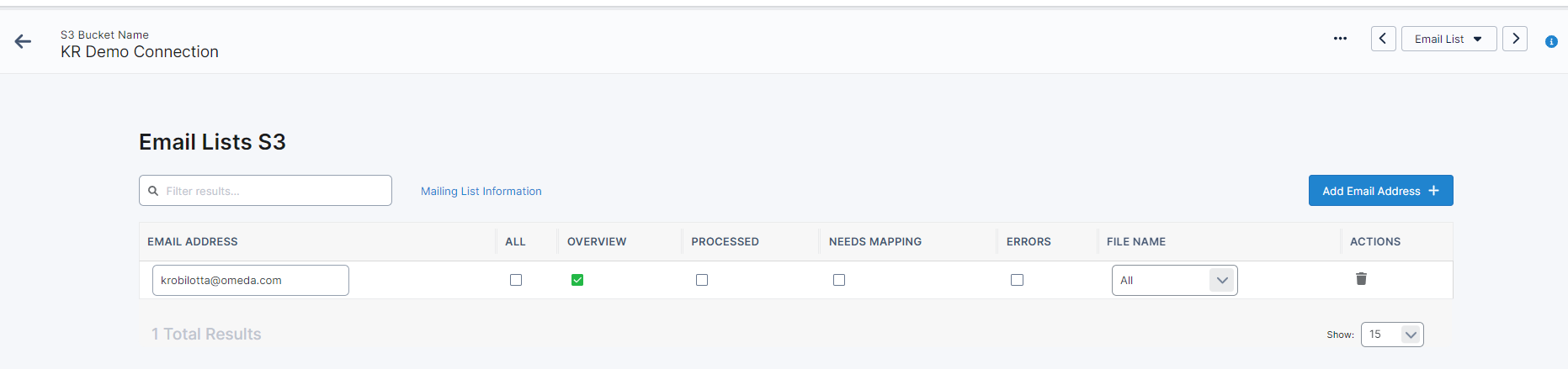
Email Lists
Email Lists will allow you to set up email addresses to receive relevant Data Loader S3 Bucket updates.
Clicking ‘Add Email Address’ will generate the following popup:
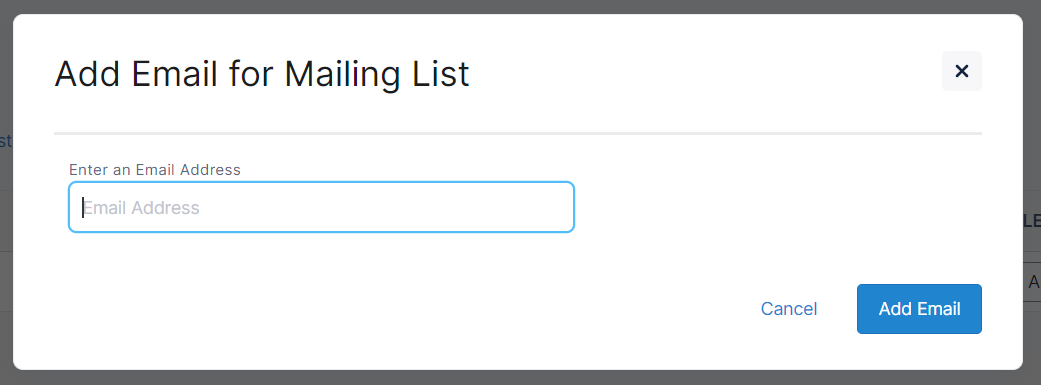
Once you have added an email address as a recipient, you can choose which type(s) of emails they will receive as well as which files they’ll receive the notifications for.
-
All: Automatically checks all of the email lists and will add the email address to all of them.
-
Overview (Checked by Default): This will send 1 (one) email every time the S3 Upload job runs. It will include stats on how the job ran. This is a brief overview of what happened; opt into other mailing lists for more detailed information, such as the “Needs Mapping” or “Errors” mailing lists.
-
Processed: This will send 1 (one) email per File that has been successfully processed during an S3 Upload job run. The resulting file will likely be in the “Completed” or “Completed with Errors” state. This is the same email that is received when a File is processed manually. If multiple files process automatically, the email address(es) will receive one email per file.
-
Needs Mapping: This will send 1 (one) email every time the S3 Upload job runs. It contains up to two different sets of information:
-
File Matched Criteria, but not Template – This will list out the files that had issues matching the Template assigned to the Tracking criteria the file’s name matched on. It will then list the items that caused it not to match the Template. This can be either mismatching headers (extra or missing) or values that have not been mapped. In any case, the File will be uploaded and the user can correct the Mapping in the Files Section, as they would if it were a manually uploaded file.
-
File didn’t Match Tracking Criteria – This will list files that existed on the S3 Bucket but could not be properly matched to a Tracking criteria. No actions were taken upon these files.
-
-
Errors: If the S3 Upload job fails, 1 (one) email will be sent informing the assigned address that something has gone wrong with the upload job. This will likely be due to an issue with how the S3 Bucket connection or Tracking criteria were setup.
Additionally, this mailing list will potentially send 1 (one) email per File that fails during the Upload or Processing steps. These will be the standard emails that are sent normally when a File fails in either situation. -
File Name: Select which file (from Manage Tracking) the recipient should receive notifications for. Otherwise, keep it defaulted to ‘All’ to receive notifications for all files uploaded to the S3 Bucket. If recipient should receive notifications for more than one file, but not all, add the Email Address to list again.
Manage Tracking
To set up how files are pulled from the S3 Bucket and ingested into your database, you’ll need to go into ‘Manage Tracking’. Files are identified and matched to templates based on tracking rules.
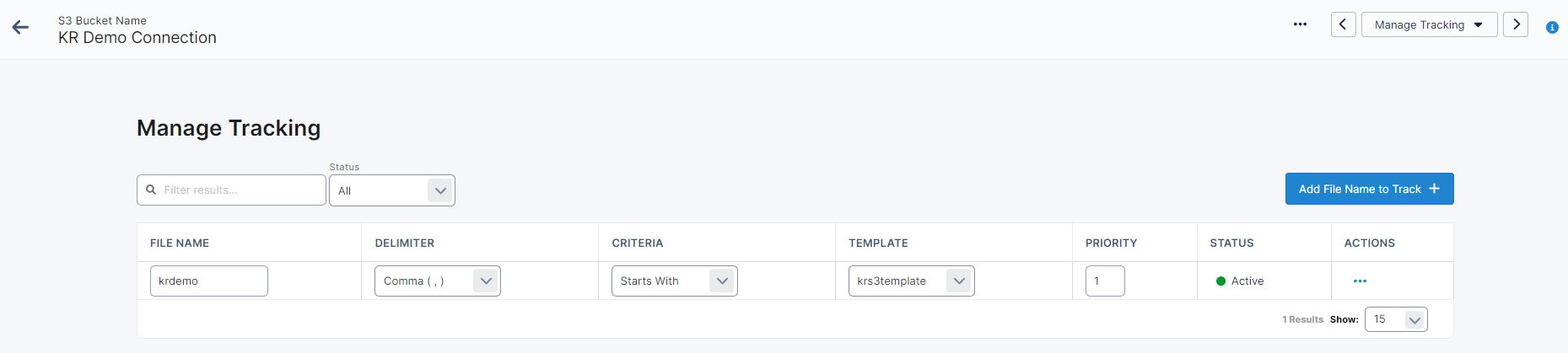
To set up a new tracking rule, click ‘Add File Name to Track’. This will open up a new popup where you will need to 1) Enter a file name 2) Note how the file is delimited, and 3) Select a saved template to apply to each of the files that fall into the track.
For more information on how to set up a template for Data Loader, see our Templates article.
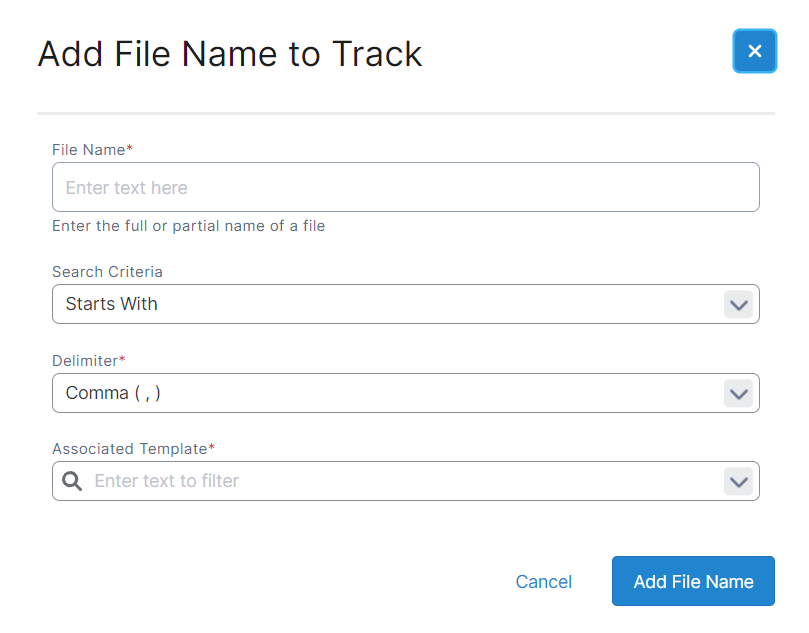
Once the track is set up, it will appear in the Manage Tracking list view. Multiple tracks can be set up and active at the same time. If multiple tracks match a file, the highest priority will be applied.

From the list view you are easily able to edit the file name, change the delimiter, adjust the match criteria, change the template and update the priority.
From the actions drop-down you can also remove and activate/deactivate tracks.
View Directory
Within the ‘View Directory’ section, you have the ability to see all of the files currently on the S3 Bucket and if they have been matched and their status.
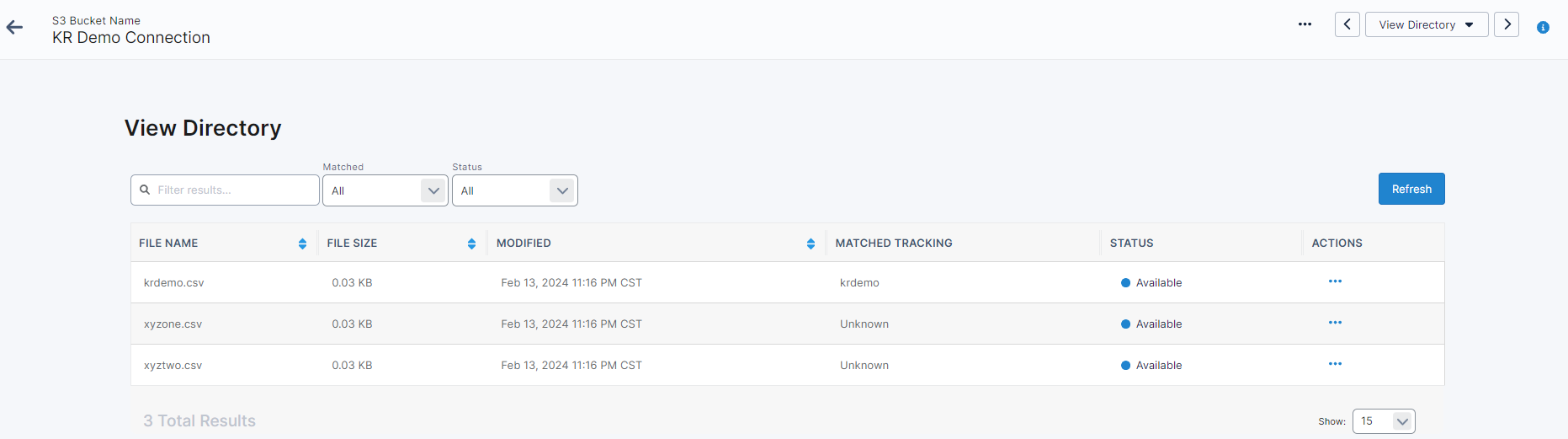
The file statuses that you will see are:
-
Available: The file can be processed if there is a matched tracking assigned. If none is assigned, you can set one up using the ‘Track File’ option under Actions.
-
Uploaded: The file was pulled in from the S3 Bucket, but couldn’t be processed (usually because the template didn’t match the file 100%). You will need to review the mapping and manually process the file via the standard Data Loader process.
-
Processed: The file was successfully pulled in, the template was applied, and the data was added to your database.
-
Failed: The file was not processed, or uploaded.
Table of Contents