The API Implementation Process
As powerful as APIs are to use, implementing them is a process. This is not as simple as just “plug and play”, and proper implementation of APIs involves testing both from your client team and Omeda’s technical and account service teams. Here are some general project planning tips for going through an API implementation.
Requirements: What am I trying to accomplish?
The first step in an API implementation is to understand the overall business requirements. There’s a reason why we’re trying to get two systems to talk to each other! What is it? Some common themes are:
-
Host your own web forms, and post the collected data back to your Omeda database.
-
Drive content on your CMS by using data in your Omeda database.
-
Pass information from an ERP system into your Omeda database.
Whatever the scenario, it’s important to determine the business requirements before proceeding to development. This avoids rework and it also helps both teams frame what’s possible (and sometimes even what’s not possible). You should be able to answer the following questions at the end of this process:
-
What database am I going to be accessing?
-
How frequently will the data be accessed? Will it be transactional?
-
Do I need to lookup data from my database?
-
What kind of data?
-
How do I plan to look it up? (by id, email address, etc.?) Will I have these data elements?
-
-
Do I need to send data back to the database?
-
What data is being sent back to be saved?
-
How frequently will these changes be saved?
-
What codes will I be using in my data? Does Omeda know how to translate them to values in my current database?
-
-
Is an API appropriate, or will a different data process be needed (file transfer, etc)?
-
Which API or APIs will I be using?
Initial Setup: Requesting Access
Once you’ve identified what it is you want to accomplish from a business perspective, your technical team will need to request an API key. This key:
-
identifies your application
-
grants access to a database (or databases)
-
grants access to the APIs you have identified in Requirements.
You are responsible for the privacy and security of this key. It should not be shared.
Once you request a key, the team at Omeda will also prepare a test environment. This test environment is populated with test data that is similar to the database. The population of this data may take a few hours, but you generally can access the test environment with your key immediately.
Development
Your development team needs time to implement each API. This involves putting code in parts of your application that calls the Omeda APIs in order to do something (lookup or post) with your data. Beyond just formatting and handling data according to the specifications, your development team should consider the following: How often will the API be called? For example, if you’re collecting data as part of a multi-page form flow, you should ideally POST the data only when the last page is reached (or on session timeout) – otherwise you may increase the risk of duplicate data being sent. How will I handle error responses from the API? Most of the APIs we have created return predictable error codes in circumstances when invalid data is sent, your API key is invalid or expired (security precaution), and even if there is a server-side problem on our end. Make sure your code can gracefully handle these scenarios appropriately, without unduly interrupting user experience. What will I do if my application can’t connect to Omeda’s APIs? The fact is that most developers tend to “plan for the best”. The wise developer plans for the worst. When two systems connect over the web, there are many things that can go wrong – some of which are not in either party’s control. Building safeguards into your application to handle such scenarios is always a good idea. Remember – the URLs for the testing environment and production environment are different! You’ll want to make sure that the API URLs are “configurable” so that when you deploy your code to production you can easily change the URLs to Omeda’s production API instances without doing a lot recompilation.
Testing
Testing is crucial. Testing is also often overlooked, because API implementations are often seen as purely a “technical” exercise. They are not! True “sign-off” is only possible when the business users have verified that the requirements are satisified. So, what are the expected results of an API implementation? These should have been determined in the initial requirements step. Here are some pointers. For APIs that involve looking up data at Omeda, some important end-user verification tests may include
-
did the data requested match what I expected?
-
is it in the right data format?
-
is the data being displayed properly?
-
can I simulate what happens when a lookup fails? does the system behave as expected?
-
can I simulate what happens when there’s a connection problem to Omeda? does the system behave as expected?
For APIs that involve storing data at Omeda, some important end-user verification tests may include
-
did the data make it to Omeda?
-
can I query it?
-
is it in the right data format?
-
did the codes I use get translated properly?
-
did the correct customer record get updated?
-
can I simulate what happens when there’s a connection problem to Omeda? does the system behave as expected?
It’s important that end-users and your account team at Omeda work together to verify the test results and resolve issues together. This ensures that no API implementation is released “until it’s time”.
Cutover
After your end-users/stakeholders sign off on the testing phase, a cutover or “go-live” event is planned. Frequently a cutover event takes place outside of peak business hours to ensure minimal disruption to user experience, but this is not always the case. Cutover generally involves the same people involved in the testing process. The Omeda technical team will enable production access for the API key. Your technical team should plan on deploying code to your own production environment (assuming you have separate testing and production environments). Also, remember that while an API key does not generally change between test and production environments, the URLs that you call to access the APIs DOES CHANGE. Make sure your technical team has taken this into account during the production deployment process.
So, generally a cutover event proceeds as follows. Prior to the cutover time window:
-
the omeda technical team will verify that any prerequisite data configuration is made on your database (data processing translation rules etc.)
At the agreed-upon cutover time window:
-
your technical team will deploy the API-enabled code to your production environment
-
the Omeda technical team will enable production access to your API keys
-
the technical team will verify they can connect to the API
-
the functional teams will conduct functional tests to verify the integration is working properly
In the event of a problem:
-
make sure your technical team can “roll-back” to the prior version of code if necessary.
Use of API Keys
Your API key is used to identify the application calling our service. Our recommendation is that you obtain an API key for each application that calls our services. This is especially true when dealing with 3rd party vendors who may be integrating with Omeda on your behalf. They should EACH get an API key. Think of API keys as usernames and passwords. Omeda uses these keys to keep track of the volume of requests coming from each individual source. This is done both for performance monitoring AND for security reasons.
It is very important that you safeguard your API key. Do not share it with individuals outside of your organization. Do not, beyond what is necessary, include it in emails, as email can easily be forwarded.
Recommendations for POST APIs
POST APIs such as Add/Update Customer and Add Order services are generally used to transmit data that you or your vendors have collected to your database on a transactional database. There are some important concepts that you should understand when using these APIs to ensure your data is handled as desired.
Use of Input Ids
Some of our POST APIs require “Input Ids”. An Input Id is a way we keep track of what data processing rules are to be applied to customer data processing. If you are using a POST API that requires the use of an Input ID, bear in mind that each POST API client application should have a distinct input id. If you use the same input id across all your applications, BEWARE! This implies you want the same exact validation, deduplication, and prioritization rules to be applied to all your data (which is hardly ever the desired case).
POST Once Per Session
The most important concept to understand about our POST APIs is that they are generally designed to be called once and only once per user session. In other words, if a customer is visiting your site over a series of web pages that collect data about him (for example, a series of registration pages) the web service POST should be called once – when the user has completed all the pages. The diagram below illustrates this:
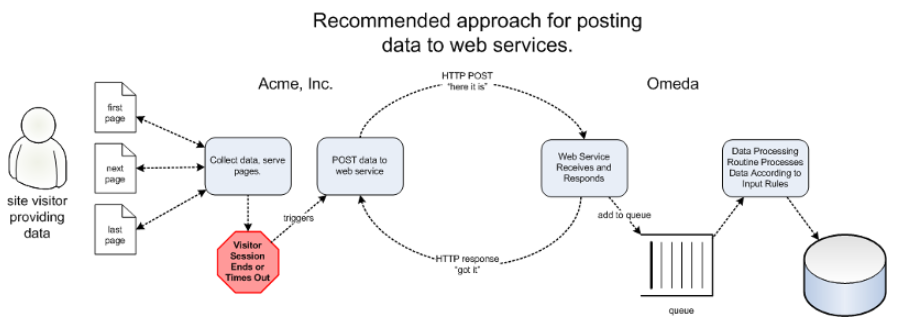
Most web programming languages (J2EE, .NET) have the ability to detect when a user’s session times out. This makes an ideal hook for calling Omeda POST APIs, because it should handle two important cases:
-
your site terminates a user’s session because they have reached the end of an interactive process. For example, you implement server-side code that terminates a registration session because a user has reached and completed the last page of the registration process.
-
your site terminates a user’s session because the session has timed out. For example, you may want to collect what data is available if a user has abandoned the registration process.
Avoid Common POST Pitfalls
A common mistake some programmers make when considering to use our POST APIs is to fire off web service POSTs after every form submission. There are a number of problems this creates:
-
Typically this introduces some amount of latency to the user experience. While most web service response times will be very fast (a few milliseconds), the additional call to a service can introduce the possibility of a delays, particularly if your general internet connections are saturated on high-volume days.
-
A higher volume of internet traffic is produced. This can be expensive in terms of per-service charges, and, as mentioned above, add latency to the user experience.
-
The risk of introducing duplicates to your database is increased. Data received by Omeda via the post services is queued for processing with each call. All of our services are stateless, which means each POST is considered a separate transaction. Thus, POSTing multiple times actually creates multiple transactions in our queue. Generally, these transactions are processed onto the database asyncronously, and depending on the duplication rules you have put in place, could lead to duplicate records being added to the database.
-
More complexity is added to the process. Programatically, you may have to implement the POST in separate areas of your code. This can introduce the probability of programming mistakes. What happens if any single call fails but others succeed? etc.
Here’s an illustration of the problems that the “repetitive POST” approach causes:
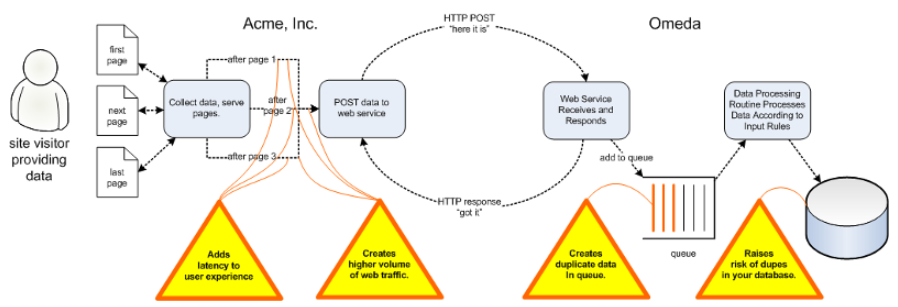
Table of Contents